为PDF自动生成目录-pdf.tocgen教程
在许多文档处理工作中,自动生成目录是一个常见的需求,尤其是对于大型PDF文档。手动创建目录可能会很繁琐且耗时,因此寻找自动化的解决方案是很有必要的。在这篇博客中,推荐一个强大的命令行工具 - pdf.tocgen,它可以帮助我们自动生成PDF文档的目录。
网上还有很多其他工具可以自动生成目录,但是基本都需要提前找到完整的目录信息,才可以为pdf生成目录。这个工具不需要完整的目录信息,只需根据一点信息,就可以从pdf自动推导出目录。因为很多时候我们无法找到pdf文件的已有目录信息,所以我推荐这个工具。
0 简介
效果
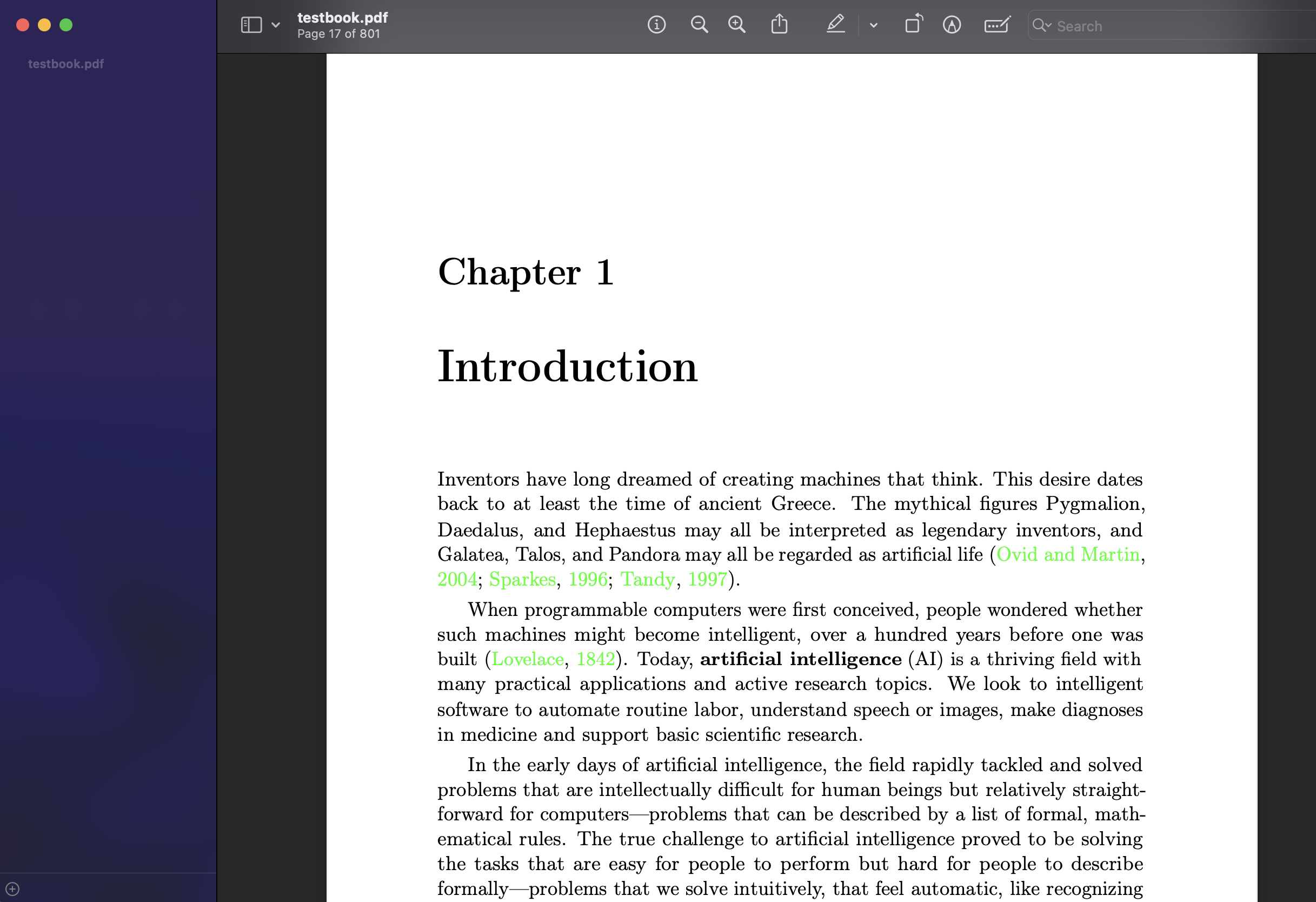
我用一本zlib上下载的pdf英文书为例,下载下来时是没有目录的,用preview打开效果如下, 可以看到左边是没有目录的。
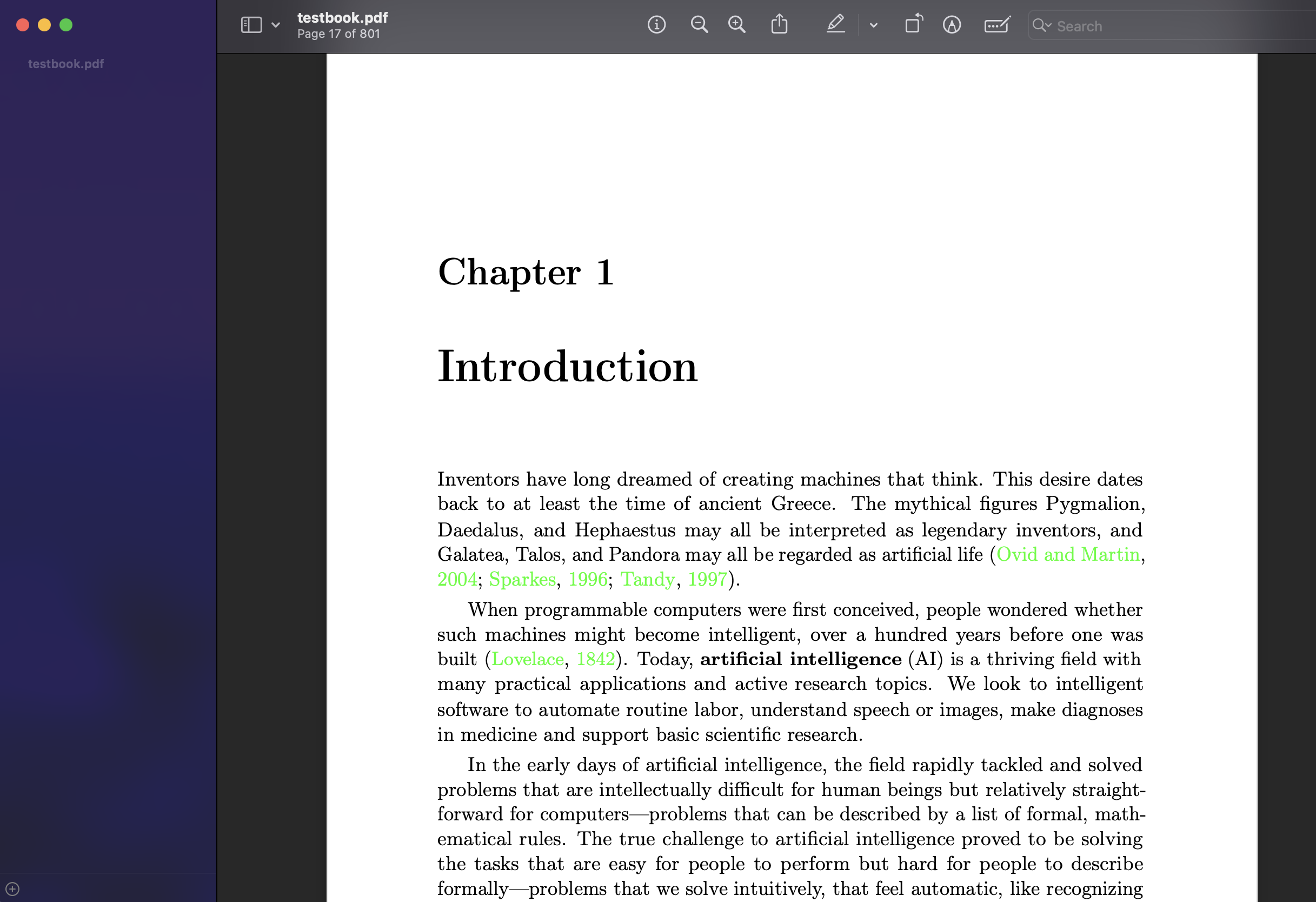
使用该工具后可以达到的效果如下,可以看到已经成功生成了目录,并且可以正确跳转。

适用条件
根据官方文档,该工具最适用于从TeX文档使用pdftex(及其相关工具如pdflatex、pdfxetex等)生成的PDF文件,但它也可以与其他软件生成的PDF文件一起使用,例如troff/groff、Adobe InDesign、Microsoft Word等。中文英文PDF都适用。
需要注意的是,扫描的PDF是不适用的。以及格式特殊的PDF(比如标题是图片不是文字形式)可能也会遇到问题。根据具体情况而定。
结构
pdf.tocgen是一套用于自动提取和生成PDF文件目录的命令行工具。它使用嵌入字体属性和标题的位置来推断PDF文件的基本大纲。由 pdfxmeta、pdftocgen、pdftocio 三个工具组成。负责的功能如下:
- pdfxmeta: 根据输入的信息,提取标题的元数据(字体属性、位置)以建立一个格式信息文件。
- pdftocgen: 通过格式信息文件生成一个目录描述文件。
- pdftocio: 根据目录描述文件,结合原始pdf,生成增添了目录的新pdf。
1 | in.pdf |
看起来稍微有些复杂,上手大概需要十几分钟,学会使用后就变得很方便。分成三个工具有它的好处,使我们更容易看到中间生成的文件内容,来判断行为是否符合我们的预期。也给了我们更大的灵活性。
下面就来介绍如何使用这个强大的工具
1. 下载
pdf.tocgen是由python3写的,在Linux、MacOS、Windows都可以运行
如果没有python环境,需要先安装python,这里就不赘述了。
在命令行输入如下命令即可安装该工具,-U选项表示如果已经安装该包,则更新它,否则下载该包
pip install -U pdf.tocgen
2. 工作流程
第一步,创建格式信息文件
我们使用pdfxmeta工具,根据pdf文件,提供目录信息,从而生成一个TOML文件,告诉pdftocgen标题、副标题等应该长什么样
我们需要告诉工具的信息有:任意标题的内容(可以用python格式的正则)、页码、是几级标题。需要注意页码是该目录在pdf中的实际页码,不一定是pdf文件内部标注的页码(比如文章开始给出的效果图中,实际页码是17,内部标注页码是1)
命令如下
1 | pdfxmeta -p 页码 -a 级别 pdf文件名 标题内容 >> 输出文件 |
输出需要是一个.toml格式文件,里面就是标题信息。
举例
我们用一个pdf书生成1和2级标题的目录信息文件
一级标题如下,我们用”Introduction”来表示标题内容
1 | pdfxmeta -a 1 -p 17 testbook.pdf "Introduction" >> recipe.toml |
输出的recipe.toml文件如下:
1 | [[heading]] |
接下来产生2级标题信息
二级标题如下,因为只需要得到标题的格式,所以提供的标题内容足够辨别出标题就行,比如这里的”1.1”可以不包含在内。最后生成的目录会自动判断出是否属于标题内容。

1 | pdfxmeta -a 2 -p 24 testbook.pdf "Who Should Read This Book?" >> recipe.toml |
现在recipe.toml文件如下:
1 | [[heading]] |
格式信息文件就这样生成好了,接下来可以进入下一步了
第二步,生成目录
第二步就很简单,只需要利用第一步的输出,用pdftocgen工具,就可以得到目录
命令如下
1 | pdftocgen PDF文件 < 元信息文件 >> 输出文件 |
输出文件可以是.txt格式,也可以不指明格式
举例
继续上面的例子
1 | pdftocgen testbook.pdf < recipe.toml > toc |
toc文件内容大致如下:
1 | "Contents" 3 |
实际上,如果不需要对目录文件进行修改的话,可以使用管道,将第二步和第三步一起执行。下面会说到。
如果目录文件正常,是我们想要的效果,就可以进入最后一步了。
第三步,将目录导入pdf中
这一步也非常简单,需要用到目录文件,原始pdf文件
命令如下
1 | pdftocio -o 目标文件名 原始pdf文件 < 目录文件 |
举例
1 | pdftocio -o result.pdf testbook.pdf < toc |
result.pdf就是文章最初,效果展示里面有目录的那个文件

我们成功的为pdf生成了目录。
结合第二步与第三步
只需用管道结合两步的命令即可
1 | pdftocgen testbook.pdf < recipe.toml | pdftocio testbook.pdf -o result.pdf |
3. 最后
因为这个工具是根据有限的信息推导出目录,所以如果pdf的格式越特殊,出错的可能性就越大,这是无法避免的。不过工具提供了很大的自由,我们可以编辑每一步的输出,来尽量达到我们想要的效果。同时这个工具还有很多更细节,更高级的用法,大家如果感兴趣,可以去看官方文档(英文)